Introduction
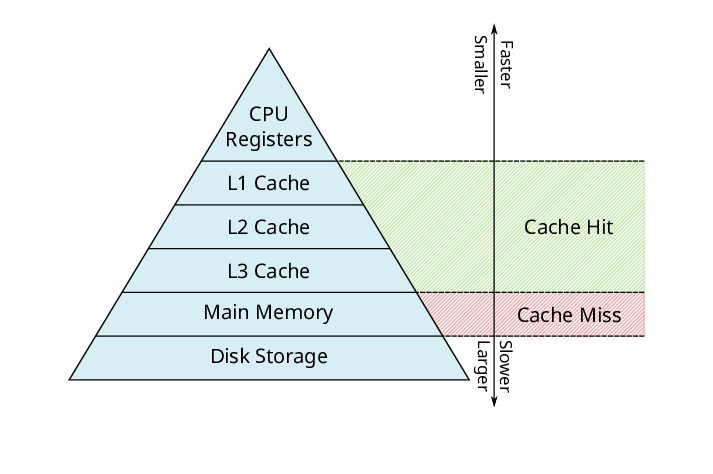
The performance of processors advances at a much faster rate than the performance of memory. This leads to an ever increasing performance gap between the processor and the memory. In order to shrink this performance gap, processors employ caches. Caches are small but faster chunks of memory to keep recently and frequently used data closer to the process. Therefore, the time to perform a memory access is not constant, as shown in the image below.
Applications like AES encryption may employ look up tables in software to speed up the process. The problem with this is that they may leak sensitive data. In the case of AES encryption, these looks up index the table using a combination of the plain text and the encryption key. During this look up, part of the table will end up in the cache. An attacker can mount a cache attack to figure out which part of the table is in the cache and can use this information to infer bits of the encryption key.
Various cache defenses exist both in software and hardware to protect against these attacks. Unfortunately, the availability and the flexibility of hardware defenses is limited. Hence we focus on software defenses instead. The basic idea behind the software defenses is that they partition the cache into separate regions that isolate the victim from potential attackers.
While these defenses are effective against cache attacks from the CPU, we demonstrate a new family of cache attacks named XLATE (translate) attacks that bypass these defenses. XLATE attacks reprogram the Memory Management Unit (MMU) to mount a cache attack. Since XLATE uses indirect cache access to achieve this, XLATE is the very first indirect cache attack.
Reprogramming the MMU
The Memory Management Unit (MMU) translates virtual addresses into their physical counterparts. To achieve this the MMU, iterates through several levels of page tables as shown below. While iterating these page tables, the MMU uses chunks of the virtual address to index each of these tables. This process is called a page table walk.
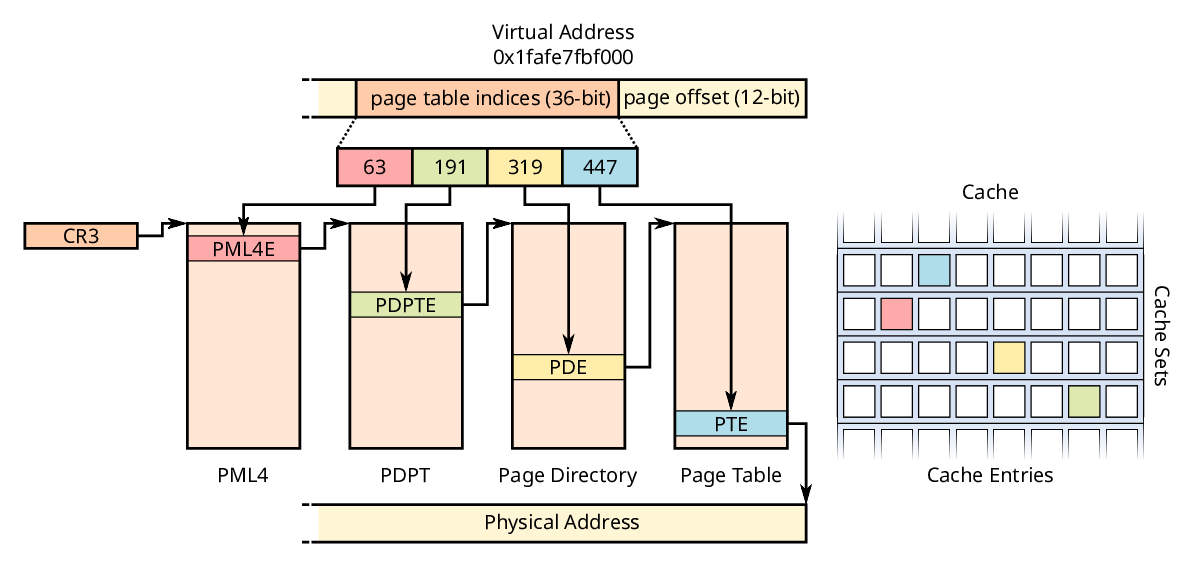
When performing a page table walk, the MMU thus performs several page table look ups. These page table look ups each result in an indirect memory access that also interacts with the cache. This means we can use the MMU to mount a cache attack. To achieve this we have to carefully control the page tables that the MMU accesses.
Translation Caches
Page table walks result into multiple additional memory accesses in addition to the one required to access virtual memory. This means that accessing virtual memory is a factor slower. To speed up virtual address translation, modern processors employ various caches. One of these caches is the translation cache. The translation cache stores part of the virtual address and the intermediate page table it points to as shown in the image below.
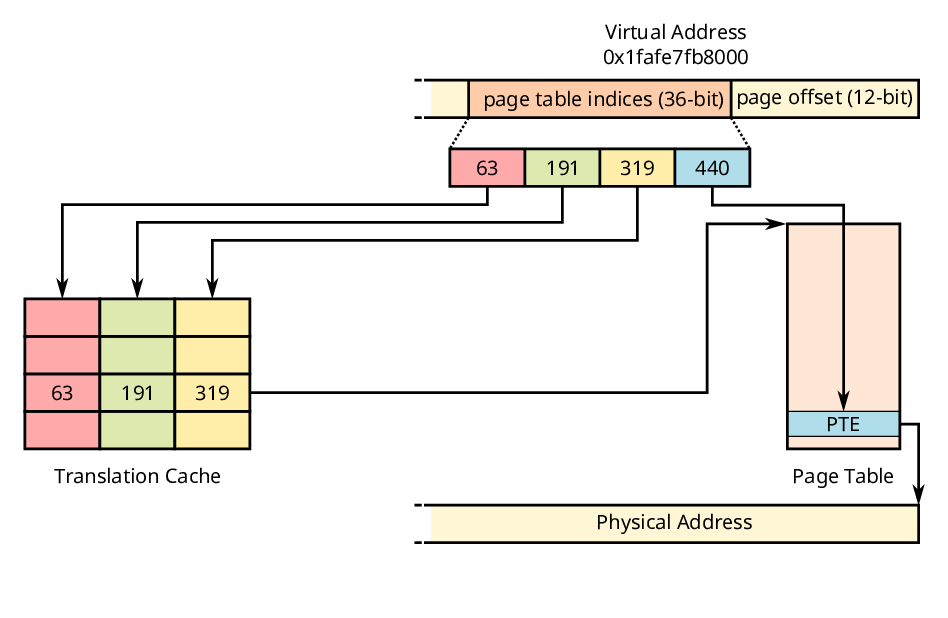
Translation caches therefore allow the MMU to skip part of the page table hierarchy for virtual addresses close to each other. Hence translation caches accelerate page table walks by reducing the amount of memory accesses needed. This is also extremely convenient for XLATE attacks, as translation caches allow an attacker to avoid noise from the higher level page tables.
Unfortunately, not all properties of translation caches are well documented. In fact, their existence might not even be. Therefore we had to reverse engineer these properties. For more information about how to achieve this, we invite you to read our
paper. We reverse engineered these for 26 different microarchitectures:
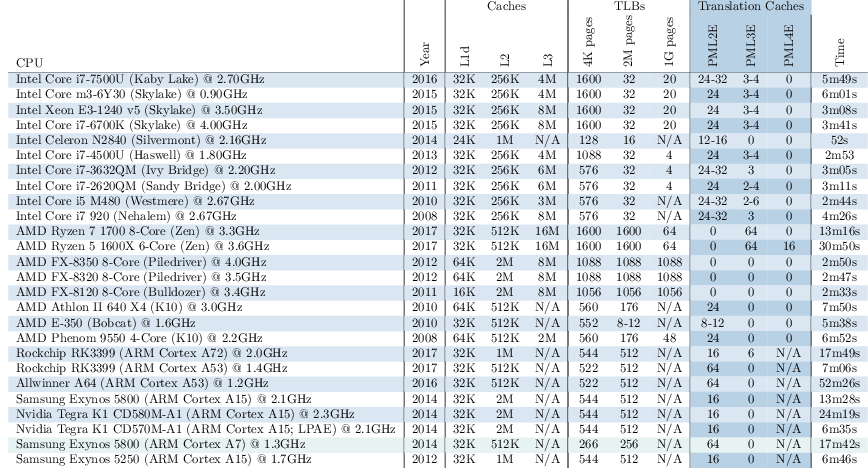
We have found that translation caches are widely available on a variety of Intel, AMD and ARM processors. This presents us with one of the ingredients needed for XLATE attacks. For a better understanding of the other two ingredients needed, we invite you to read our
paper.
Results
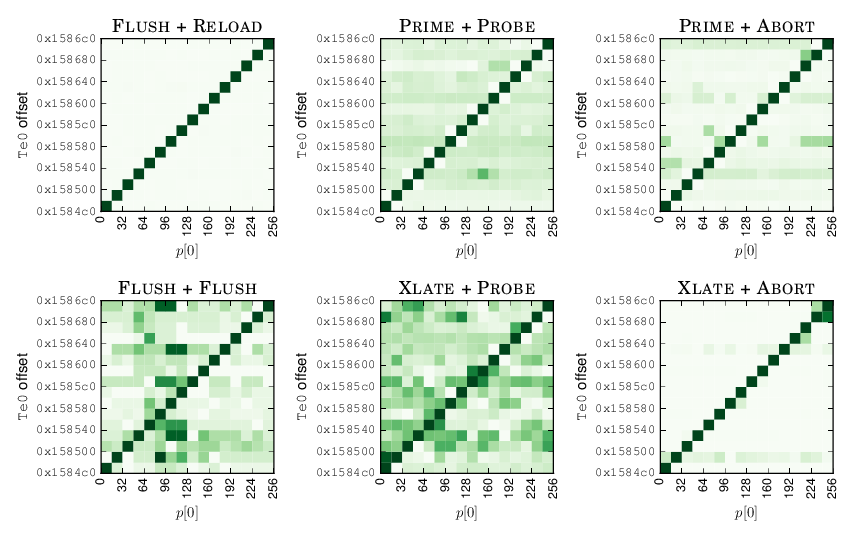
To test the effectiveness of our cache attacks, we use the T-table AES implementation in OpenSSL 1.0.1e. We implemented two variations of our cache attacks, namely XLATE + PROBE and XLATE + ABORT. As a reference, we also implemented four of the existing cache attacks in addition to our own. The image below shows that all six cache attacks are able to extract bits from the encryption key.
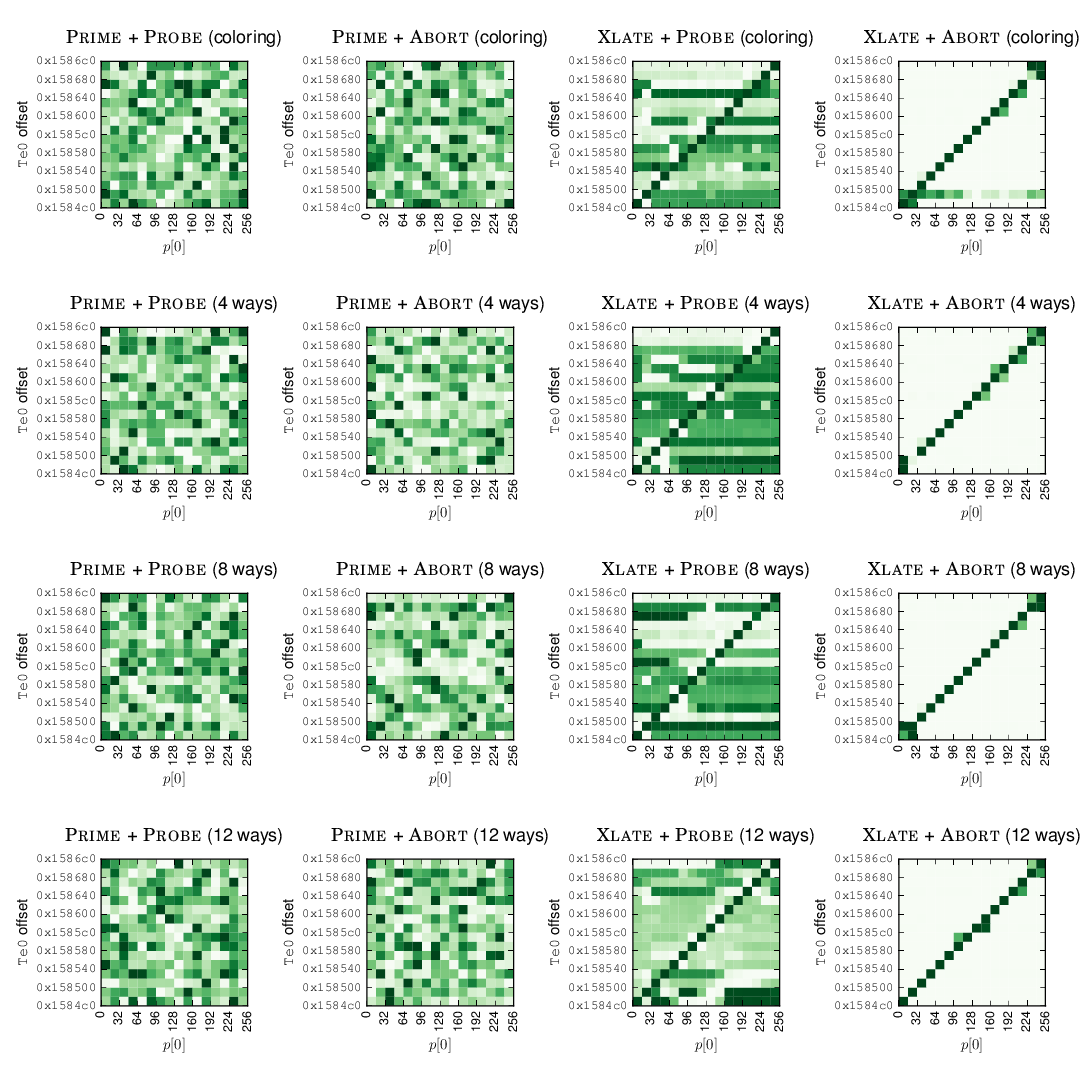
To further test the effectiveness of our attacks, we also implemented the existing software defenses to see whether they can bypass these. The image below shows that PRIME + PROBE and PRIME + ABORT are mitigated by these defenses. However, XLATE + PROBE and XLATE + ABORT are still able to bypass these.
For more extensive results, we invite you to read our
paper.
Frequently Asked Questions
- I am really interested in reading your paper, where can I find it?Both our paper and the BibTeX to cite it can be found at the USENIX website.
- Where can I find the code?The code can be found on Github.
- Do you have some demos I could check out?Yes, we have a selection of videos available on YouTube.
- Is it possible to extend existing defenses to protect against these attacks?Software-based defenses using way partitioning would have to be able to instrument individual accesses to the page table from the MMU. There is currently no hardware that allows this. Therefore, the only realistic option is to extend page coloring to also include page tables to the security domains.
- Are there any other components suitable for indirect cache attacks?We expect that the kernel can be tricked into performing the memory accesses required to mount an indirect cache attack. Furthermore, System-on-Chips (SoCs) integrate various components in addition to the CPU on the same chip, such as GPUs to give one example. If the caches are shared between the CPU and these components, it might also be possible to trick such components to mount an indirect cache attack.
Papers
Acknowledgements
This project was supported by the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 786669 (ReAct), by the MALPAY project, and by the Netherlands Organisation for Scientific Research through grants NWO 639.023.309 VICI “Dowsing”, NWO 639.021.753 VENI “PantaRhei”, and NWO 629.002.204 “Parallax”. The public artifacts reflect only the authors’ view. The funding agencies are not responsible for any use that may be made of the information they contain.
