
A Systematic Analysis of Machine Clears and Their Implications for Transient Execution Attacks
TL;DR
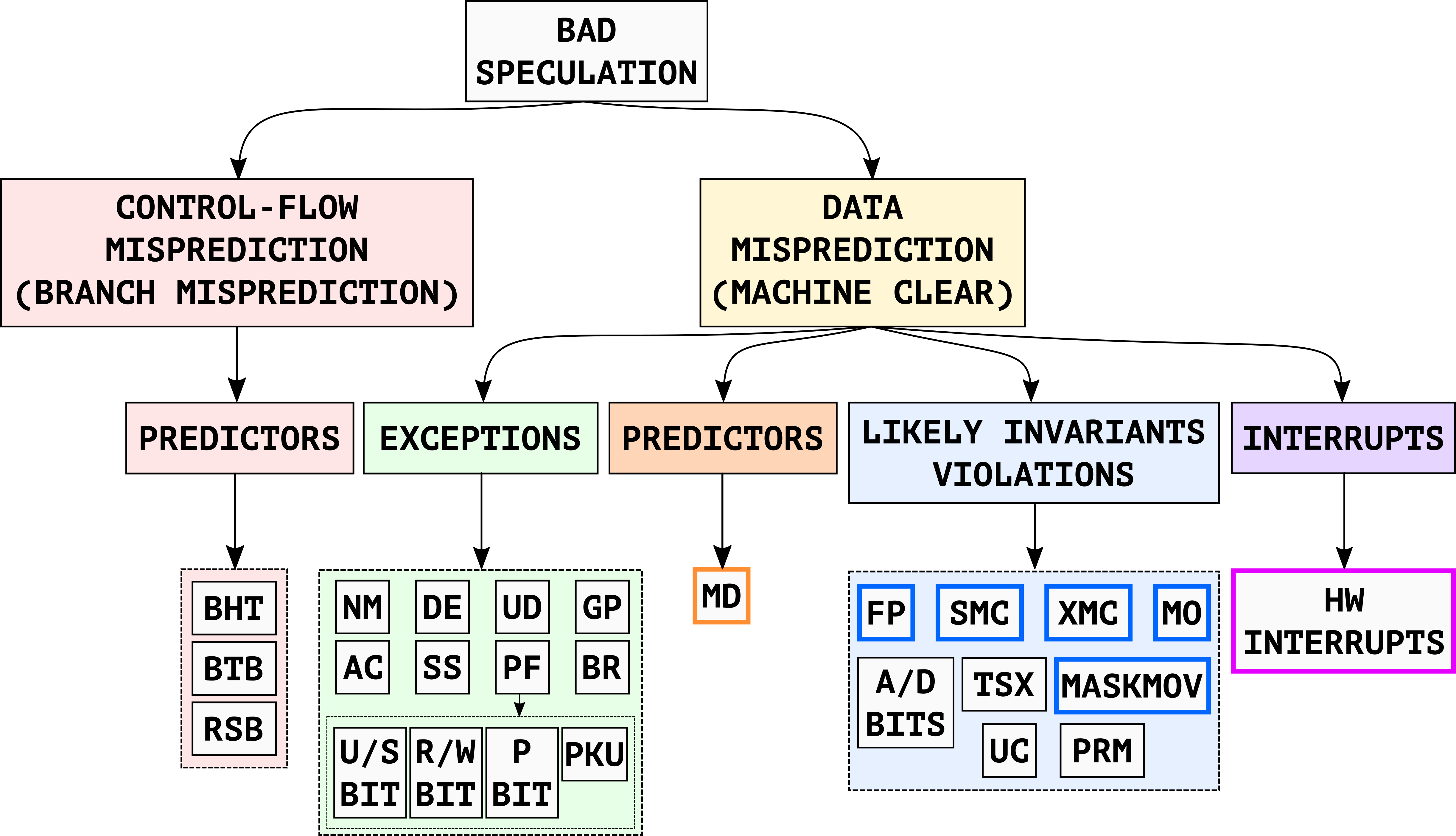
Intel refers to the root cause of discarding issued µOps as Bad Speculation, and classifies this matter into two main subclasses:
- Branch Misprediction: A misprediction of the direction or target of a branch by the branch predictor will squash all µOps executed within a mispeculated branch.
- Machine Clear (MC): A machine clear condition will flush the entire processor pipeline and restart the execution from the last retired instruction.
After the discovery of the Spectre and Meltdown vulnerabilities, most of the transient execution attack variants found, simply built on the well-known class of branch mispredictions and the aborts of Intel TSX (which is no longer supported on recent processors).
In this work, we perform the first deep and systematic analysis of the class of transient execution based on machine clears (MC), reverse engineering the corresponding (previously unexplored) root causes such as Floating Point MC, Self-Modifying Code MC, Memory Ordering MC, and Memory Disambiguation MC.
We show these events not only originate new transient execution windows that widen the horizon for known attacks, but also yield entirely new attack primitives:
Speculative Code Store Bypass (SCSB)
INTEL – CVE-2021-0089 / AMD – CVE-2021-26313
SCSB allows an attacker to execute stale, controlled code in a transient execution window created by a Self-Modifying-Code machine clear, which potentially affects JIT engines in modern web browsers running attacker-controlled JavaScript code, OS kernels, and hypervisors storing code pages and allowing their execution without first issuing a serializing instruction.
Floating Point Value Injection (FPVI)
INTEL – CVE-2021-0086 / AMD – CVE-2021-26314
FPVI allows an attacker to inject arbitrary floating-point values in a transient execution window created by a Floating-Point machine clear. With this attack primitive we can mount an end-to-end exploit on the latest Mozilla SpiderMonkey JavaScript engine with all the mitigations enabled, resulting in an arbitrary memory read in Firefox through attacker-controlled and transiently-injected floating-point results (FIREFOX – CVE-2021-29955).
In light of the newly discovered root causes of transient execution, we compare both the leakage rate and the window size of all known transient execution windows, showing the strengths and weaknesses of the different root causes. Finally, we present a new orthogonal root-cause-centric classification of the different transient execution paths to better accommodate the new causes discovered in this work.
Our Machine Clear paper (PDF) is accepted for publication at the 30th USENIX Security Symposium 2021.
- FPVI JavaScript exploit demo on Firefox
- RE Code, testing tools and JS FPVI exploit code
- Affected CPUs
- Frequently Asked Questions
/TL;DR
Causes of Machine Clear on x86 Processors
Self-Modifying Code Machine Clear
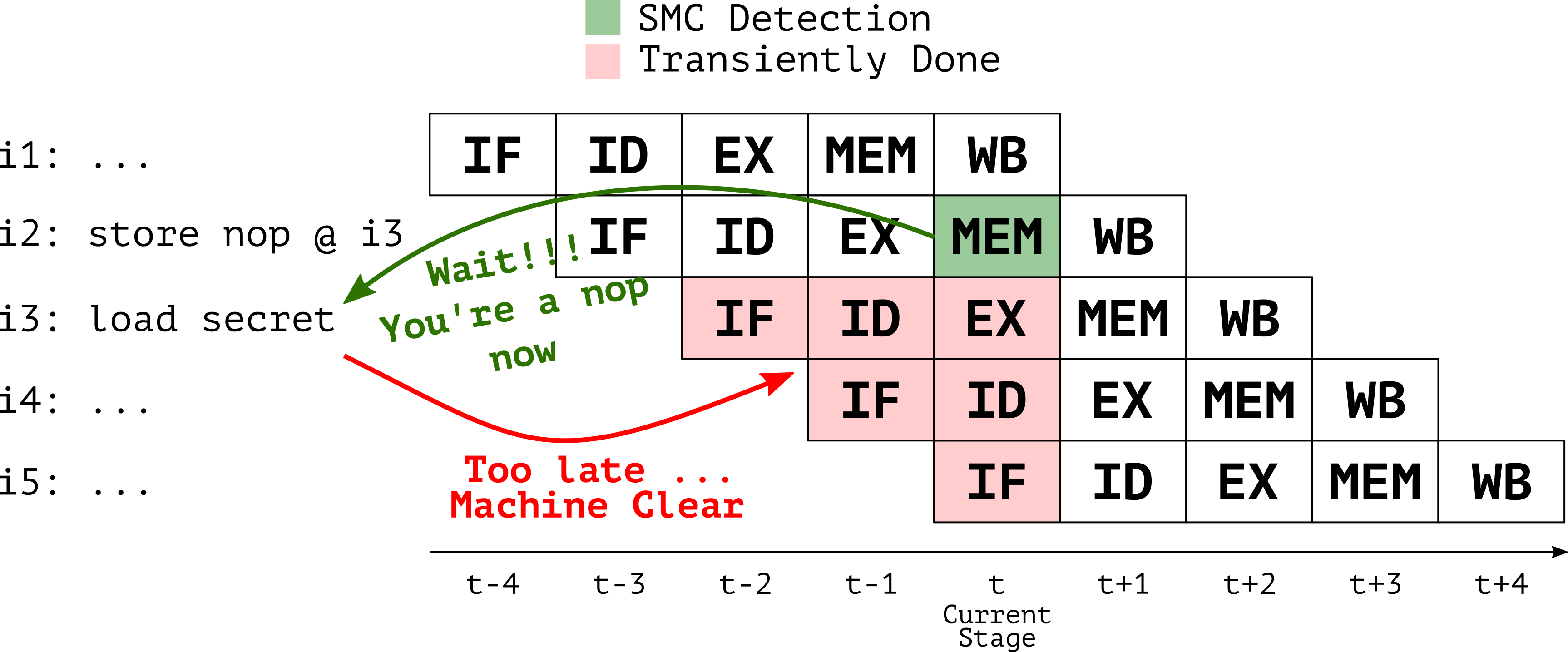
On x86/64 processors, store instructions may write instructions as data and modify program code as it is being executed. This is commonly referred to as Self-modifying Code (SMC). Managing SMC is a laborious task for modern front-ends which speculatively fetch and decode the instructions and feed them to the execution units, well ahead of retirement (i3, i4, i5 in Figure 1). Indeed we observed that whenever SMC store instructions (i2) target cache lines in the L1 Instruction Cache (i3: load secret), the processor is forced to flush its pipeline and restart the execution from the freshly updated code (i3: nop). Since SMC detection is not immediate, this creates a transient window where the instruction and data views of the memory are inconsistent, causing a transient execution of stale code (i3: load secret and all dependent subsequent instructions).
Floating-Point Machine Clear
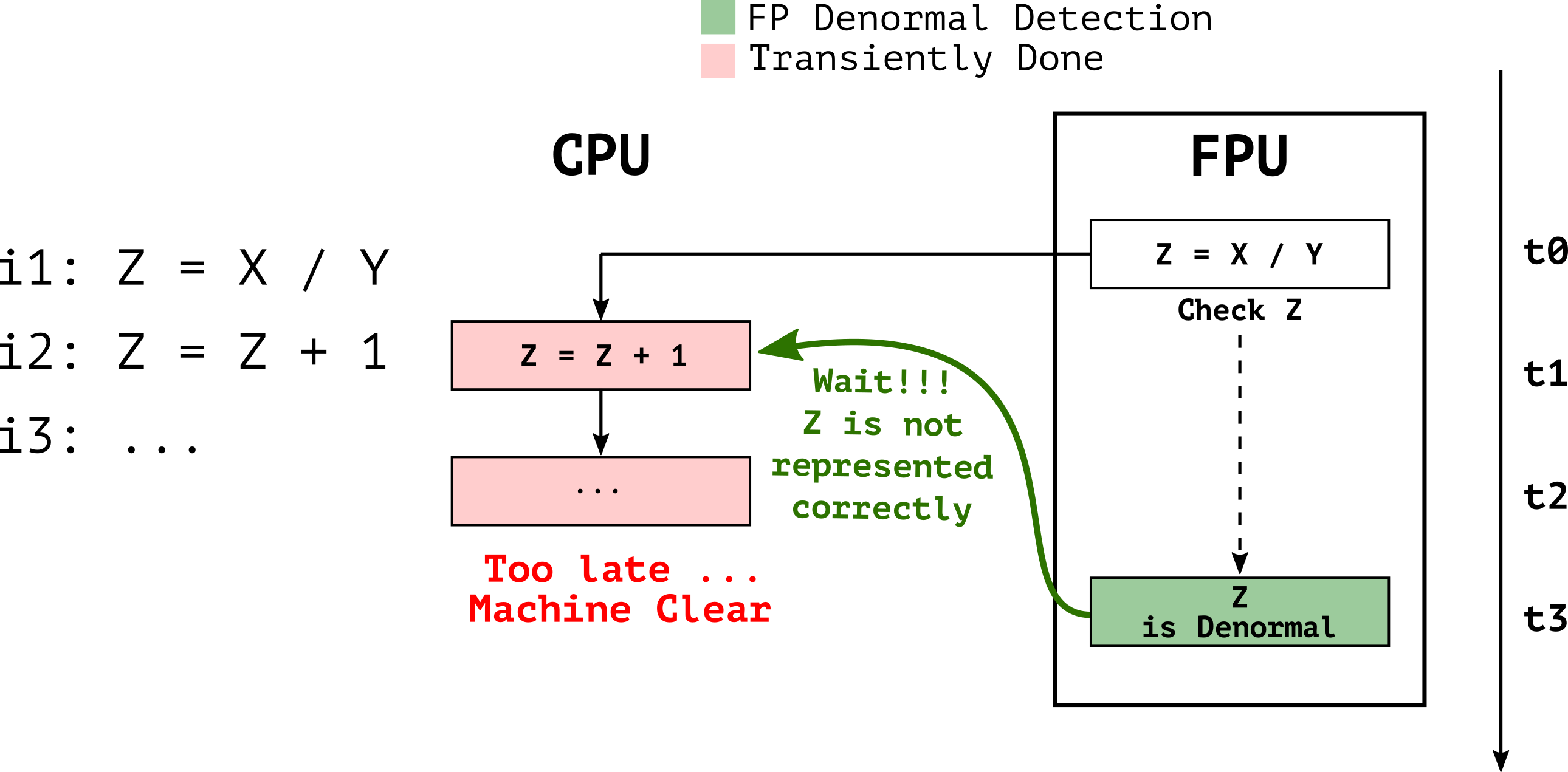
The Floating Point Unit (FPU) in modern x86 processors assume to operate on normal numbers representable with specific precision (i.e. fast path), thus floating-point operations such as Z=X/Y in Figure 2 are executed “blindly” assuming both the operands and result are normal numbers. In the case of either the operands or the result is a denormal number (slow path), as the case of Z in Figure 2, the FPU is unable to produce results in the IEEE-754 format due to the special binary representation of denormal numbers precision. Since the hardware implementation of denormal numbers representation is too complex, denormal numbers are handled through a microcode assist which triggers a machine clear.
A machine clear implies a pipeline flush, therefore, the assisted FP operation (Z=X/Y) will be squashed together with subsequent µOps (Z=Z+1) and re-executed with the correctly represented result. We verified that many FP operations can trigger FP assists (i.e., add, sub, mul, div and sqrt) across different ISA extensions (i.e., x87, SSE, and AVX).
Memory Ordering Machine Clear
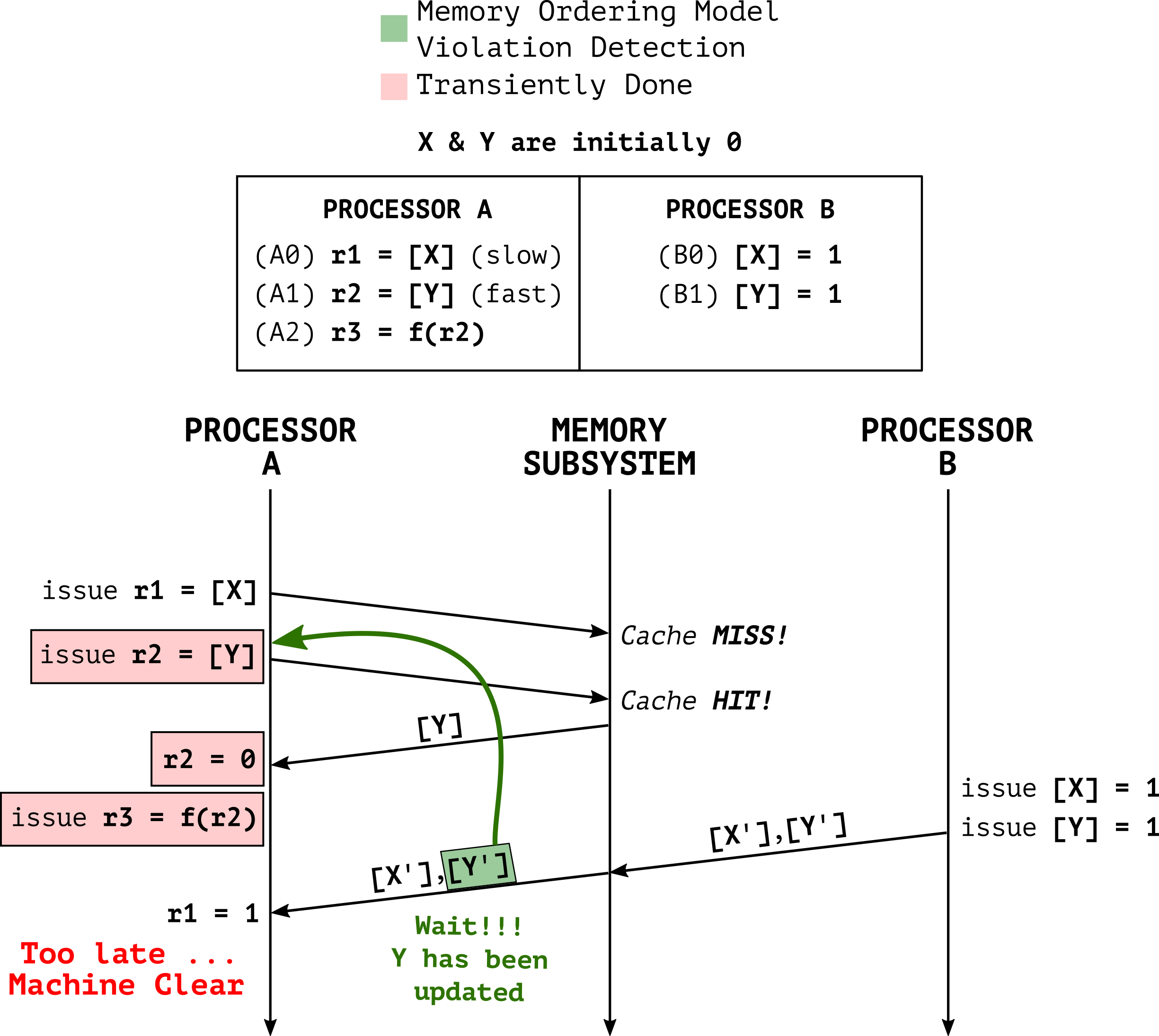
On x86/64 processors, a Total-Store-Order (TSO) memory ordering model is used. This model ensures that all cores see all memory operations in the same order as specified by the program, except a single case: a store followed by a load on a different address may be reordered.
A memory ordering MC is created every time the processor is uncertain if the memory ordering will be preserved. Figure 3 shows an example where due to a slow load operation (A0) and aggressive out-of-order execution (A1) causing a violation of the memory ordering model. To fix this issue, the processor is forced to squash all transiently executed instructions (i.e. A1 and all its subsequent instructions).
As shown in Figure 3, this MC allows core B to trigger core A to first transiently execute A1 on a stale value of Y, and then architecturally re-execute A1 on the new value written by core B.
Memory Disambiguation Machine Clear
Memory disambiguation (MD) is a micro-architectural predictor that enables the processor to schedule load and store operations out of program order. MD allows to speculatively execute loads before the address of previous stores is known. In case of a misprediction, a machine clear is required to squash the load operation which accessed stale data. In appendix A of the paper, we present additional MD reverse engineering results on top of the previous work done by Travis D.
Other Causes of Machine Clear
We explored other causes of machine clear, such as:
- AVX vmaskmov
- Exceptions
- Hardware interrupts
- Microcode assists
For more details regarding these types, please check our paper.
Transient Execution Capabilities
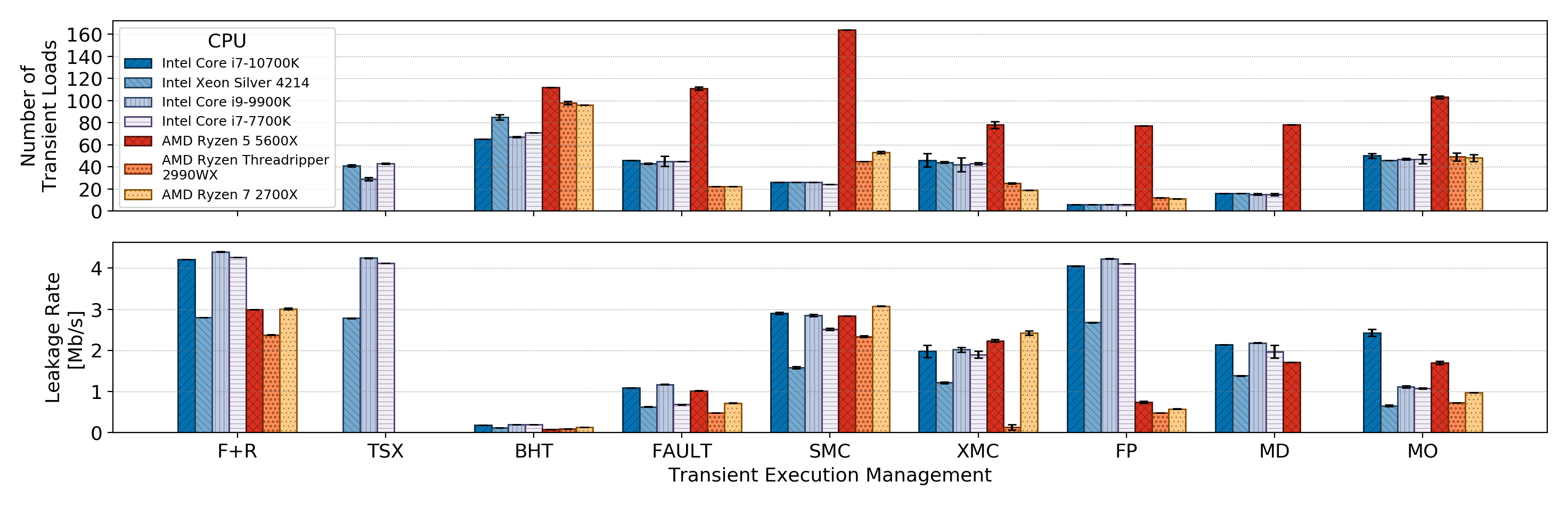
Transient execution attacks rely on crafting a transient window to issue instructions that are never retired. For this purpose, state-of-the-art attacks traditionally rely on mechanisms based on root causes such as branch mispredictions (BHT), faulty loads (Fault), or memory transaction aborts (TSX). However, the different machine clears discussed in this paper provide an attacker with the exact same capabilities.
To compare the capabilities of machine clear-based transient windows with those of more traditional mechanisms, we implemented a framework able to run arbitrary attacker-controlled code in a window generated by a mechanism of choosing. We evaluated our framework on recent processors (with all the microcode updates and mitigations enabled) to compare the transient window size and leakage rate (Figure 4) of the different mechanisms.
Speculative Code Store Bypass (SCSB)
INTEL – CVE-2021-0089 / AMD – CVE-2021-26313
The transient window generated by a SMC can be abused by an attacker to transiently execute arbitrary code. To understand how let’s consider a JIT engine (e.g JavaScript) in Figure 5 where the following 3 steps are performed:
- The attacker forces the JIT of a function F that overwrites part of a previously present code G, where the attacker managed to find a transient gadget.
- The attacker, by executing F, induces the processor to transiently execute G instructions since the code and data views are not coherent. This transient stale code execution will leave an observable micro-architectural trace.
- Finally, the processor will fix the SMC MC by flushing the pipeline and restarting the execution from the newly written code.
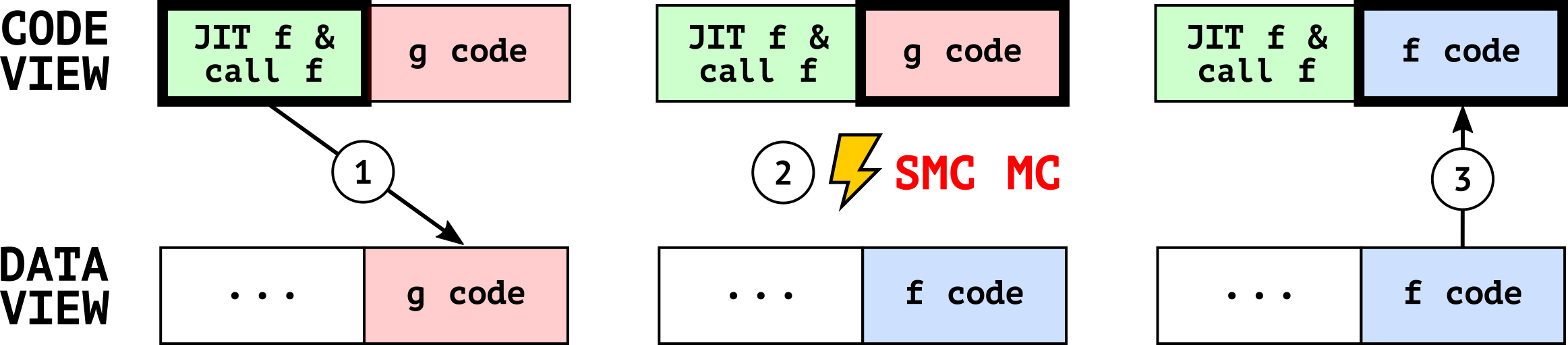
This attack, at a high level, yields a transient use-after-free primitive on code cache and is conceptually similar to a Speculative-Store-Bypass (SSB). For this reason, was named Speculative Code Store Bypass (SCSB). Overall, while the exploitation is far from trivial (i.e., having to address use-after-free and transient execution exploitation in the browser), we believe SCSB expands the attack surface of transient execution attacks in the browser.
Interestingly, the Intel Architectures SDM in Figure 6 suggests handling SMC with “Option 1” that describes the exact steps required by SCSB, potentially resulting in exploitable gadgets.

Mitigation
As confirmed by Intel, SCSB can be mitigated by placing a serializing (e.g. lfence, mfence, cpuid, etc.) instruction after the SMC store operation as suggested in “Option 2”.
Floating-Point Value Injection (FPVI)
INTEL – CVE-2021-0086 / AMD – CVE-2021-26314
Floating Point Value Injection (FPVI), allows an attacker to inject arbitrary values into a transient execution window originated by an FP machine clear.

As exemplified in Figure 7, the operations of the exploit can be broken down into four steps:
- The attacker triggers the execution of a gadget starting with a denormal FP operation in the victim application, with the x and y operands under the attacker’s control.
- The transient z result of the operation is processed by the subsequent gadget instructions, leaving an observable microarchitectural trace.
- The CPU detects the error condition (i.e., the wrong result of a denormal operation), triggering an FP machine clear and thus a pipeline flush.
- The CPU re-executes the entire gadget with the correct architectural z result.
For exploitation, we found exploitable gadgets in NaN-Boxing implementations of modern JIT engines. NaN-Boxing implementations encode arbitrary data types as double values, allowing attackers running code in a JIT sandbox (and thus trivially controlling operands of FP operations) to escalate FPVI to a speculative type confusion primitive. The latter can be exploited similarly to NaN-Boxing-enabled architectural type confusion and allows an attacker to access arbitrary data on a transient path. Figure 7 presents our end-to-end exploit for a JavaScript-enabled attacker in a SpiderMonkey (Mozilla JavaScript runtime) sandbox, illustrating a gadget unaffected by all the prior Mozilla Firefox mitigations against transient execution attacks.
For example, using 0xc000e8b2c9755600 and 0x0004000000000000 as division operands yields -Infinity as the architectural result and our target string pointer 0xfffb0deadbeef000 as the transient result (see gadget in Figure 8). Note that SpiderMonkey uses no guards or Spectre mitigations when accessing the attribute length of the string. This is normally safe since x86 guarantees that NaN results of FP operations will always have the lowest 52 bits set to zero—a representation known as QNaN Floating-Point Indefinite. In other words, the implementation relies on the fact that NaN-boxed variables, such as string pointers, can never accidentally appear as the result of FP operations and can only be crafted by the JIT engine itself. Unfortunately, this invariant no longer holds on an FPVI-controlled transient path. As shown in Figure 7, this invariant violation allows an attacker to transiently read arbitrary memory. Since the length attribute is stored 4 bytes away from the string pointer, the z.length access yields a transient read to 0xdeadbeef000+4.
Mitigation
- The most efficient way to mitigate FPVI is to disable the denormal representation. On Intel, this translates to enabling the Flush-to-Zero and Denormals-are-Zero flags, which respectively replace denormal results and inputs with zero. However, this defense may break common real-world (denormal-dependent) applications, a concern that has led browser vendors such as Firefox to adopt other mitigations.
- Another option for browsers is to enable Site Isolation, but JIT engines such as SpiderMonkey still do not enable this by default as a production implementation.
- Yet another option for JIT engines is to conditionally mask (i.e., using a transient execution-safe cmov instruction) the result of FP operations to enforce QNaN Floating-Point Indefinite semantics, as done in the SpiderMonkey FPVI mitigation.
- A more general and automated mitigation is for the compiler to place a serializing instruction, such as lfence, after FP operations whose (attacker-controlled) result might leak secrets by means of transmit gadgets (or transmitters). We have implemented such mitigation in LLVM, measuring an overhead of 32% / 53% on SPECfp 2006/2017 (geomean).
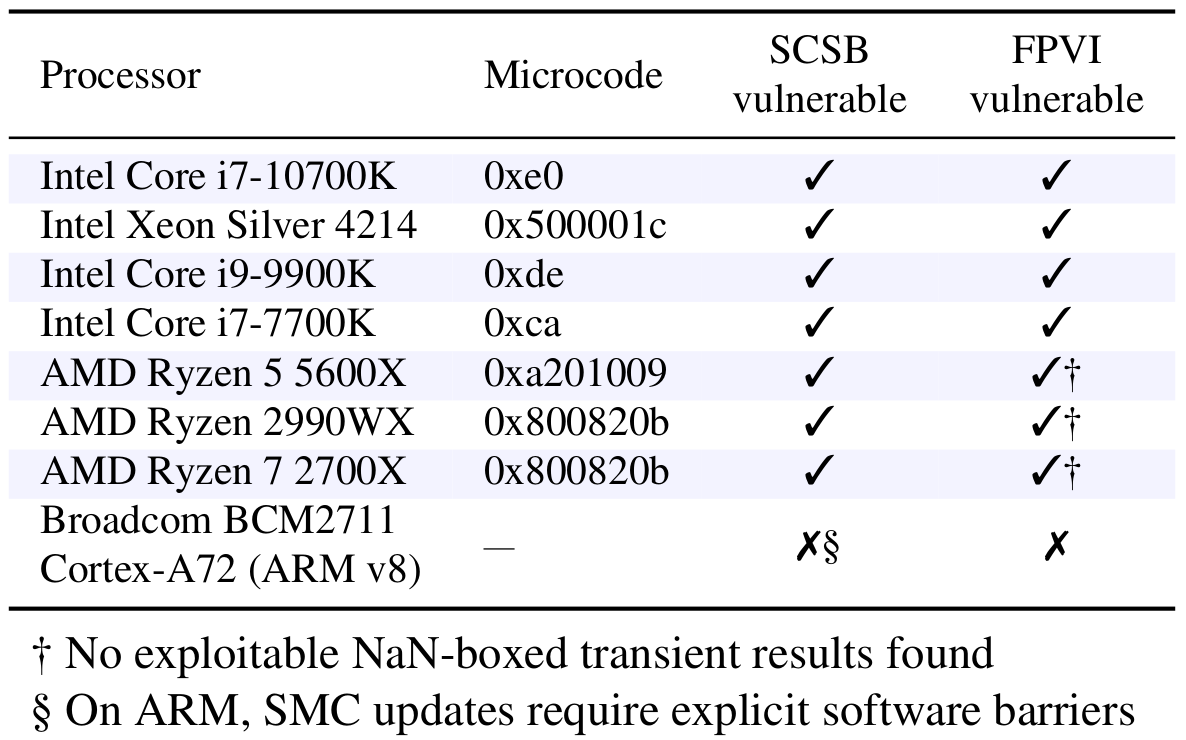
Affected CPUs
Both Intel and AMD processors are affected by FPVI and SCSB. In Figure 8 we list the CPUs we tested in our experiments. Intel published the complete list of all its affected processors (Columns FPVI & SCSB). AMD confirmed that all its CPUs are affected. ARM confirmed our results of not being affected by SCSB and reported that some FPU implementations are affected by FPVI.
Classification of the Root-Causes of Transient Execution
To better characterize the capabilities of transient execution exploits, we propose a new root-cause-based classification in Figure 9. This classification is orthogonal to earlier, attack-oriented classifications and better distinguishes the root causes of the transient execution windows. In particular, we identify two main classes of root causes of Bad Speculation (i.e., transient execution): Control-Flow Misprediction (i.e., branch misprediction) and Data Misprediction (i.e., machine clear).
Based on these two main classes, we observe that all the known root causes of transient execution paths can be classified into the following four subclasses:
- Predictors
- Exceptions
- Likely invariants violations
- Interrupts
For more details about the different root-cause classes, please check our paper.
FPVI Exploit Demo on Firefox
PoC||GTFO
You can find reverse engineering code, testing tools, and a complete ready-to-run FPVI JavaScript exploit at https://github.com/vusec/fpvi-scsb
Disclosure
We disclosed Floating-Point Value Injection and Speculative Code Store Bypass to CPU, browser, OS, and hypervisor vendors in February 2021. Following our reports, Intel confirmed the FPVI (CVE-2021-0086) and SCSB (CVE-2021-0089) vulnerabilities, rewarded them with the Intel Bug Bounty Program. AMD also confirmed the FPVI (CVE-2021-26314) and SCSB (CVE-2021-26313) vulnerabilities. Both Intel and AMD released their security advisories (INTEL-SA-00516, AMD-SB-1003) with recommendations in line with our proposed mitigations. ARM confirmed that some FPU implementations are vulnerable to FPVI. Mozilla confirmed the FPVI vulnerability (CVE-2021-29955), rewarded it with the Mozilla Security Bug Bounty Program, and deployed a mitigation based on conditionally masking malicious NaN-boxed FP results in Firefox 87. The Xen hypervisor mitigated SCSB and released a security advisory (XSA-375) following our proposed mitigation.
FAQs
The logo is free to use, rights waived via …. ah, no, wait, we don’t have a logo, but if you really insist you can grab one here.
Different Intel and AMD processors are affected by both primitives as shown in the affected processors‘ section. Regarding FPVI, our Firefox exploit works only on Intel CPUs with Firefox < 87.0.
Regarding SCSB, we found several candidate gadgets in real-world code, but none of them was ultimately exploitable due to the coincidental presence of some serializing instruction preventing stale code execution. Nonetheless, mitigations are needed to enforce security-by-design. Indeed, the Xen hypervisor mitigated SCSB following our proposed mitigation.
Check our proposed mitigations here.
Check our proposed mitigations here.
Both FPVI and SCSB are hardware vulnerabilities. Vulnerable software happens to rely on legitimate x86 architectural invariants which vulnerable CPUs violate on transient execution paths.
Neither Intel nor AMD is planning on releasing any microcode updates or hardware mitigations and suggests following its updated software guidance linked in the corresponding security advisories INTEL-SA-00516 and AMD-SB-1003 (in line with our recommendations).
Both primitives allow attackers to inject controlled values into transient execution. However, the underlying issues and hence the triggering conditions are fairly different. LVI requires the attacker to induce faulty or assisted loads on the victim’s execution. FPVI imposes no such requirement but does require an attacker to directly or indirectly control operands of a floating-point operation in the victim. Nonetheless, FPVI can extend the existing LVI attack surface and also provides exploitation opportunities in new scenarios.
SCSB is conceptually similar to a Speculative-Store-Bypass (SSB) primitive, but can transiently execute stale code rather than reading stale data. However, the underlying causes of the two primitives are quite different (i.e. MD misprediction vs. SMC machine clear).
Acknowledgements
We thank our shepherd Daniel Genkin and the anonymous reviewers for their valuable comments. We also thank Erik Bosman from VUSec and Andrew Cooper from Citrix for their inputs, Intel and Mozilla engineers for the productive mitigation discussions, Travis Downs for his MD reverse engineering, and Evan Wallace for his Float Toy tool. This work was supported by the European Union’s Horizon 2020 research and innovation program under grant agreements No. 786669 (ReAct) and 825377 (UNICORE), by Intel Corporation through the Side-Channel Vulnerability ISRA, and by the Dutch Research Council (NWO) through the INTERSECT project.